Note
This technote is not yet published.
Describe the EFD architecture, data replication, retention policies, etc
1 Introduction¶
DMTN-082 [3] presents a proposal to enable real-time analysis of the EFD data in the LSST Science Platform (LSP). SQR-029 [1] describes a prototype implementation of the EFD based on the Confluent Kafka Platform and the InfluxData stack and reports results of live tests with the LSST T&S Service Abstraction Layer (SAL) including latency characterization and performance evaluation with high-frequency telemetry. SQR-031 [2] describes the EFD Kubernetes-based deployment using Kubes (k3s), a lightweight Kubernetes, that allowed us to exercise the deployment and operation of the EFD at the Auxiliary Telescope (AT) test stand in Tucson and at the Summit in Chile while we implement the final on-premise deployment platform.
In this technote, we introduce the concept of source EFD for instances deployed at the Summit and Test stands that collect data from the hardware, and aggregator EFD that aggregate data from the source EFDs and is deployed at the LDF. The aggregator EFD is meant to be a single place where scientists connect to perform their analysis. We describe new components added to the EFD architecture, in particular, we discuss data replication from the source EFDs to the aggregator EFD, retention policies, and options for long-term storage of the EFD data.
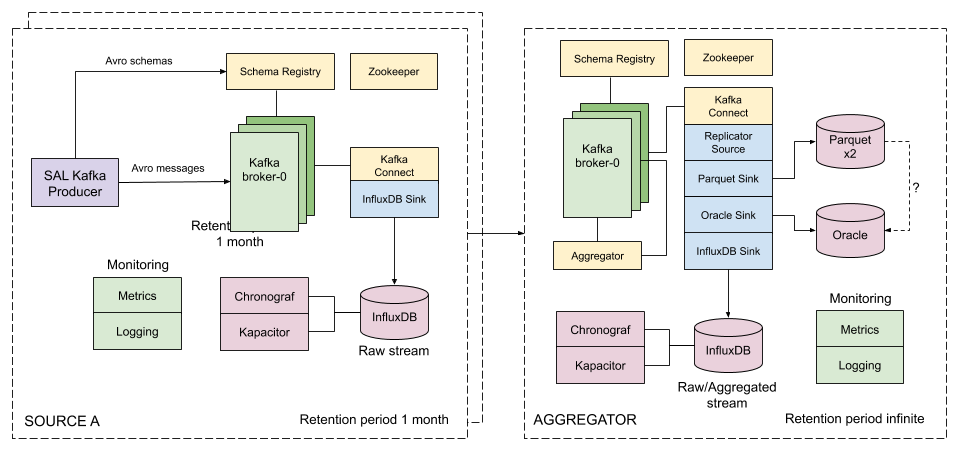
Figure 1 Architecture for the source and aggregator EFDs.
2 The SAL Kafka producer¶
The SAL Kafka producer runs only on source EFDs (Summit and test stands) and forward DDS messages from one or more SAL components to Kafka. For each DDS topic, SAL Kafka introspects the OpenSplice IDL, creates the Avro schema and uploads it to the source Schema registry dynamically. The Kafka brokers cache the Avro serialized messages, and consumers use the Avro schemas created by SAL Kafka to deserialize them.
SAL Kafka was an important addition to the EFD architecture, it decouples the EFD from the SAL XML schemas and introduces Avro as the interface between the DDS middleware and Kafka.
3 The Kafka Connect manager¶
Another addition to the EFD architecture is the Kafka Connect manager. The Kafka Connect manager is the component responsible for managing the Kafka Connect REST interface. It is used to deploy the different connectors to the EFD. For connectors that are not dynamic like the InfluxDB Sink and the JDBc Sink connectors, the Kafka Connect manager can automatically update the connector configuration when new topics are created in Kafka.
4 Data replication and fault tolerance¶
The EFD uses Kafka to replicate data from the source EFDs (primary sites) to the aggregator EFD (secondary site). The Kafka Connect Replicator source connector is the component responsible for that. In the EFD setup, the Replicator source connector runs in one direction pulling topics from the primary sites to the secondary site.
New topics and schemas in the source EFDs are automatically detected and replicated to aggregator EFD. As throughput increases, the Replicator automatically scales to accommodate the increased load. By replicating topics and schemas across primary and secondary sites further protects the EFD against data loss.
In the present setup, consumers at the source EFD only read data from the source EFD and consumers at the aggregator EFD only read data from the aggregator EFD with the exception of the Replicator consumer. Within the Kafka cluster we have fault tolerance by replicating the Kafka topics across three brokers (default set up). That’s done by the SAL Kafka producer creating topics with a replication factor of three.
If the InfluxDB instance in one of the primary sites die, the InfluxDB instance on the secondary site can be used to access the data. However, there’s no failover mechanism that automatically connects a consumer to the secondary site.
In summary, the aggregator EFD provides long-term storage and a live backup of the EFD data (see 5 Downsampling and data retention).
5 Downsampling and data retention¶
The EFD writes thousands of topics with frequencies ranging from 1Hz to 100Hz. Querying the raw EFD data on large time windows can be quite painful, especially at the primary sites with limited computing resources.
A natural solution is to downsample the raw data and store one or two versions of low-resolution data for extended periods. In InfluxDB, it is possible to configure multiple retention policies. For instance, at the primary sites we can have 1 week of raw data, 1 month of an intermediate resolution version of the data, and 1 year of a low resolution version of the data. The retention policy is such that data older than the retention period is automatically deleted. The result is a moving time window on the most recent data in each case. Downsampling is efficiently done inside InfluxDB using Flux tasks that can be scheduled during daytime if necessary. Similar retention policies at the LDF can be configure so that we can query the data efficiently over extended periods.
Real-time analysis of the EFD data might include statistical models for anomaly detection and forecasting. For example, InfluxDB implements a built-in multiplicative Holt-Winter’s function to generate predictions on time series data. At the Summit, if we store 1 week of raw EFD data, that’s roughly 0.2% of the data collected over the 10-years survey. If that’s sufficient to build a statistical model or not depends on the long term trends and seasonality of the time-series we are analyzing. An interesting possibility of the present EFD architecture is to build the statistical models at the aggregator EFD where we have the raw data stored for longer periods and apply the models at the primary sites when configuring alerts.
6 The Aggregator¶
As proposed in DMTN-082 [3], the LSP users are generally interested in telemetry data at a frequency closer to the cadence of the observations. It proposes that “all telemetry topics sampled with a frequency higher than 1Hz are (1) downsampled at 1Hz and (2) aggregated to 1Hz using general statistics like min, max, mean, median stdev”. Commands and event topics should not be aggregated as they are typically low-frequency and can be read directly from the raw EFD data sources.
In addition, the aggregator should resample the telemetry topics in a regular time grid to make it easier to correlate them.
The aggregator stream-processor produces a new set of aggregated telemetry topics in Kafka that can be consumed and stored in Parquet, Oracle and InfluxDB. That gives the user multiple options to combine the aggregated telemetry with the exposure table which resides in the Oracle database:
- inside the LSP notebook environment using Pandas data-frames after querying the exposure table and reading the telemetry data from one of the sources above;
- inside the Oracle database joining the exposure and the telemetry tables using SQL;
- Inside InfluxDB using Flux
sql.from()function to retrieve data from the exposure table.
All these “joins” are based on timestamps.
An interesting option for implementing the Aggregator is Faust, a Python asyncio stream processing library. Faust supports Avro serialization and multiple instances of a Faust worker can be started independently to distribute stream processing across nodes or CPU cores.
7 Options for long-term storage at the LDF¶
The LSP benefits from accessing data stored in Parquet format, which is compatible with Dask used to scale computations across multiple worker nodes. The Confluent Kafka connect storage-cloud connector recently added support to Parquet on S3. From the connector configuration, it is also possible to partition data based on time. We might want to store both the raw EFD data and the aggregated EFD data in Parquet files, which also serves as a cold backup of the EFD data.
We plan on storing the aggregated EFD data in Oracle, which is convenient to make joins with the exposure table as discussed in the 6 The Aggregator session. The Kafka Connect JDBC connector supports Oracle databases through the JDBC driver for Oracle. The JDBC Sink connector automatically creates the destination tables if the auto.create configuration option is enabled, and can also perform limited auto-evolution on the destination tables if the auto.evolve configuration option is enabled. An alternative, is to load data to the Oracle database from Parquet files in batch, but then we lose the convenience of creating and evolving the database schema offered by JDBC Sink connector.
We can store the raw data for more extended periods in the aggregator EFD than in the source EFDs. We might consider InfluxDB enterprise to build an InfluxDB cluster or even pay for InfluxDB Cloud. Alternatively, we can have multiple retention policies in InfluxDB and store low-resolution versions of the data for extended periods as discussed in the 5 Downsampling and data retention session.
8 Monitoring¶
For monitoring the Kafka cluster, we use Prometheus deployed with the Confluent Kafka Helm charts, and eventually, the Confluent Kafka Control Center. For InfluxDB, we collect system metrics from a different number of Telegraf plugins. We intend to ingest the EFD logs in the logging infrastructure at Summit and the LDF as well.
9 Appendix A - Configuring the Kafka Connect Replicator source connector¶
We’ve added the Kafka Connect Replicator source connector version 5.3.1 to our Kafka Connect container image and tested topic replication and schema migration.
In this setup, the topic replication works in one direction. The Replicator source connector consumes topics from the source cluster and the Kafka Connect workers produce topics to the destination cluster. Replicated topics are namespaced to indicate their origin. For example, summit.{topic} indicates that the topic is replicated from the Summit EFD, etc.
Schema migration follows the continuous migration model. The Replicator continuously copy schemas from the source cluster to the destination cluster Schema Registry, which is set to IMPORT mode. Schema translation ensures that subjects are renamed following the topic rename strategy when migrated to the destination Schema Registry.
An example of configuration for the Replicator that includes topic and schema replication with schema translation can be found here.
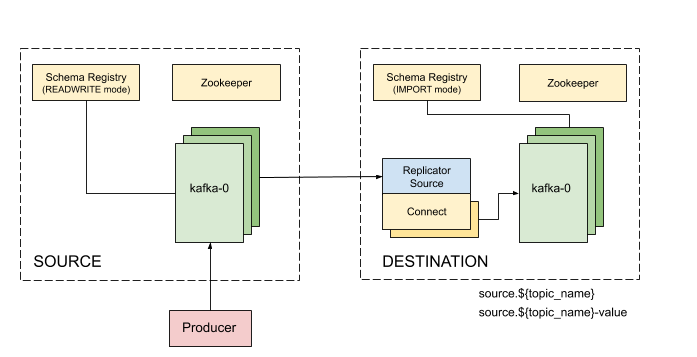
Note That Kafka Connect bootstrap.servers configuration must include the URL of the destination Kafka cluster and that the destination Schema Registry must be in IMPORT mode. To initialize the destination Schema Registry to IMPORT mode, first set mode.mutability=True in the configuration and make sure the destination Schema Registry is empty.
Confluent’s recommendation is to deploy the Replicator source connector at the destination cluster (remote consuming). However, in our current set up the Summit EFD and Tucson test stand EFD are behind the NOAO VPN. We successfuly deployed the Replicator source connector at the source clusters (remote producing). We have tested the later set up to replicate data from the Summit EFD and Tucson test stand EFD to our EFD instance running on Google Cloud. Another good practice is to have a separate Kafka Connect deployment for the Replicator source connector, to isolate this connector from other connectors running in the cluster.
10 References¶
| [1] | [SQR-029]. Frossie Economou. DM-EFD prototype implementation. 2019. URL: https://sqr-029.lsst.io |
| [2] | [SQR-031]. Angelo Fausti. EFD deployment. 2019. URL: https://sqr-031.lsst.io |
| [3] | (1, 2) [DMTN-082]. Simon Krughoff. On accessing EFD data in the Science Platform. 2018. URL: https://dmtn-082.lsst.io |